V8 doesn't just run your JavaScript. It bets on it.
Figma, Notion, and VS Code all run in the browser. They are large applications with complex state, real-time collaboration, and very large codebases. JavaScript was originally designed as a simple scripting language for web pages, so engines like V8 had to do more than just run code.
V8 watches how your code behaves, gathers evidence about the patterns it sees, and then optimizes the parts that run often enough to matter. In many cases, that optimized code becomes machine code close to what you would expect from a lower-level language.
It does this in four stages. Here is what happens under the hood.
The Core Idea: Earn Your Optimization
V8 doesn't optimize everything upfront. That would be wasteful. Most of your code runs once at startup and is never seen again. Instead, V8 uses a simple principle:
Watch first, optimize later and only optimize what's worth it.
The pipeline has four tiers. Each tier produces faster code, but takes more time and information to get there. V8 moves your code up the tiers as it earns the investment. But interestingly, it can also move code back down if the assumptions it made turn out to be wrong. We call that deoptimization.
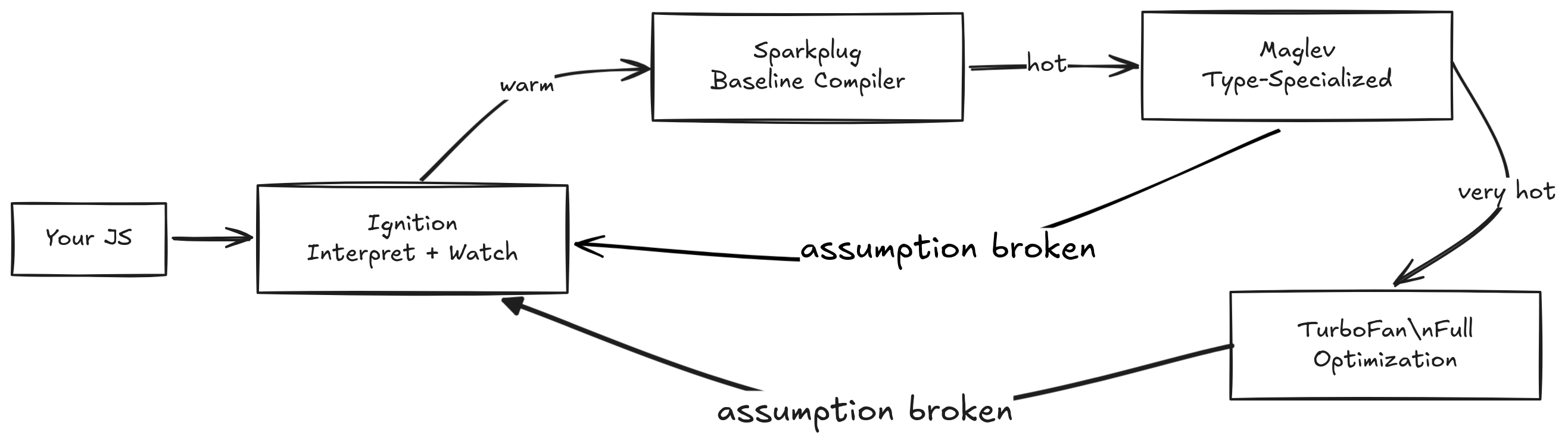
Let's walk through what happens at each stage.
Pre-stage 1 - Parsing: Making Sense of Text
Before anything runs, V8 has to understand what your code means.
It reads your source file as plain text, breaks it into tokens (const, add, =, function, ...), and builds an Abstract Syntax Tree. It's a structured, tree-shaped representation of your program.
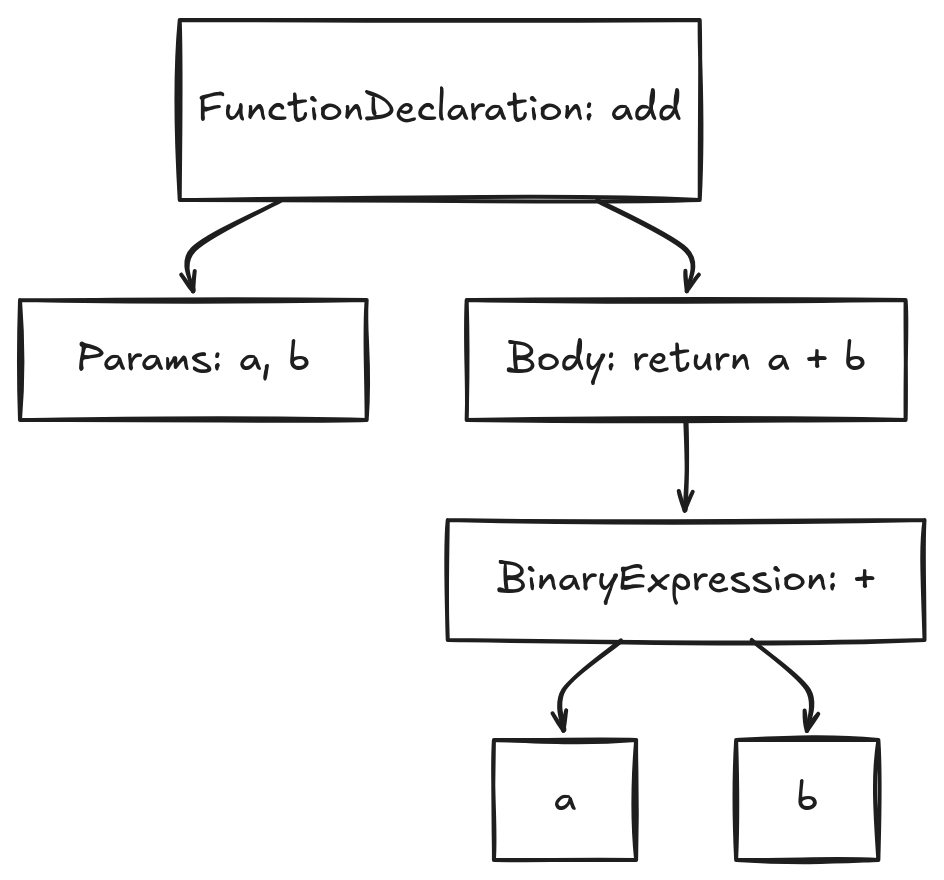
Nothing has executed yet.
Stage 1 - Ignition: The Interpreter That Watches
The AST gets handed to Ignition - V8's interpreter. Ignition walks the tree and compiles it to bytecode: a compact, lower-level set of instructions that V8 can execute directly. This bytecode is stored in memory and it's there for the lifetime of the function. It is not discarded after the first run.
Bytecode isn't machine code. It's platform-independent and simpler than native instructions. For our add function, the bytecode looks roughly like:
function add(a, b) {
return a + b;
}
// Ignition bytecode (conceptual)
Ldar a // load 'a'
Add b // add 'b' to it
Return // return the resultIgnition executes this bytecode. It reads one instruction at a time, then dispatches to the right handler. This handler is just pre-written machine code. So this is the first time your code is actually running on the CPU.
For code that runs once like startup logic, config loading, route definitions, they stay here. It's fast enough for that.
But for code that runs repeatedly, Ignition is doing something else too. It's watching.
The Invisible Evidence Log
Every function that runs under Ignition gets a hidden Feedback Vector. It is like an evidence log attached to the function. But what is it recording? There are a lot of things that are interesting to know about how a function is being used at runtime:
- How many times has it been called? (helpful to know if it's hot or not)
- If there is any loop, how many times has it iterated? (helpful to know if it's hot even if it's called once)
- What types of arguments is it receiving? (helpful to know if it's stable enough to optimize)
- What shapes of objects is it working with? (helpful to know if it can inline property access)
- What values is it returning? (helpful to know if it can specialize the return type)
- Is it calling other functions? Which ones? (helpful to know if it can inline those calls)
All these information is useful for one thing: to decide if the function is worth optimizing, and if so, how to optimize it. For example, if add() is called 847 times and always receives small integers, that's a very strong signal that it can be optimized to a single CPU instruction.
Function: add
- Called 847 times
- Argument 'a': always a small integer
- Argument 'b': always a small integer
- Result: always a small integer
- Type feedback: stableThis log is the fuel for everything that comes next. When a function is identified as "hot"(based on the feedback vector), V8 promotes it to the next tier: Sparkplug.
Stage 2 - Sparkplug: Machine Code Without the Thinking
Sparkplug is V8's baseline compiler introduced in 2021. Now what does it do? Sparkplug does something deceptively simple: it translates the bytecode one-to-one into native machine code, with no analysis and no optimization.
I mean literally one-to-one. Each bytecode instruction becomes a fixed sequence of machine instructions that can handle any possible input. For example, the add bytecode has to handle numbers, strings, BigInts, and so on. It would look roughly like this:
// Sparkplug's machine code (conceptual)
get 'a' from memory
get 'b' from memory
is 'a' a small integer? -> if not, jump to slow path
is 'b' a small integer? -> if not, jump to slow path
add them -> fast path
did it overflow? -> handle that
slow path:
call runtime to handle strings, floats, BigInt, anything else
return resultNote: Small integers (called "Smis" in V8) are special. In a 64-bit architecture, V8 can represent small integers directly in the pointer itself, without needing to allocate separate memory in the heap. V8 uses the least significant bit of the pointer to indicate whether it's a Smi or a heap object. If the bit is 0, it's a Smi; if it's 1, it's a pointer to a heap object. This allows V8 to perform very fast arithmetic operations on small integers without the overhead of memory access.
So why bother?
You see, our ultimate goal is to use all of those feedback vector insights to get to the point where we can generate machine code that assumes certain things about the inputs. Sparkplug is the first step in that direction. It gives us machine code instantly, without needing to wait for the more complex analysis that next tiers will do.
We want to be very sure about those assumptions before we make them. Sparkplug gives us a safe, unoptimized machine code baseline to run and update the feedback vector with even more precise information. It's like a test drive before we start making bets.
Stage 3 - Maglev: Now We Start Making Bets
After Sparkplug has been running for a while, V8 has a much richer picture of how your function is actually being used. Then it promotes to Maglev, the mid-tier optimizing compiler(introduced in 2023). It's where things start getting interesting.
Maglev takes the bytecode and the type feedback Ignition collected, and generates code that's specialized for what it actually saw. If add() always received integers, Maglev generates integer-specific machine code, not generic "handle anything" instructions.
// Maglev's machine code (conceptual)
// ONE-TIME CHECK (Guard)
is 'a' a small integer? -> if not, DEOPTIMIZE (go back to Sparkplug)
is 'b' a small integer? -> if not, DEOPTIMIZE
// THE "GOOD ENOUGH" WORK
add 'a' and 'b' // No more type checks here
did it overflow? -> if so, handle it
return resultThis is called speculative optimization. Maglev is betting that the types it saw in the past will keep showing up in the future. If it's right, the code runs significantly faster. If it's wrong, V8 discards the optimized code and falls back.
Maglev works in the philosophy that "good enough code that runs fast is better than perfect code that takes forever to generate." It doesn't try to be perfect. It just tries to be good enough for the common case, and it has a safety net (deoptimization) if it turns out to be wrong.
Stage 4 - TurboFan: The Full Gamble
For the absolute hottest code like functions called thousands of times with rock-solid, consistent type feedback, V8 promotes to TurboFan, the advanced optimizing compiler.
TurboFan makes aggressive bets. After seeing your add() function called 10,000 times with integers, it doesn't just generate integer-optimized code, it generates code that assumes integers forever, with no safety checks. And it means it doesn't collect any more feedback vector information either.
// TurboFan's machine code (conceptual)
// ANALYSIS: "I saw 'a' and 'b' come from a loop that only goes 1 to 10."
// CONCLUSION: "The sum can never exceed 20. Overflow is impossible."
// THE OPTIMIZED WORK
add 'a' and 'b' // No type checks. No overflow checks.
return result // Pure, raw math.
Compare that to what a generic "could be anything" add operation has to do: check if it's a number, check if it's an integer or float, handle BigInt, handle string concatenation, allocate memory if needed... TurboFan throws all of that away.
Inlining
TurboFan also performs function inlining. If your hot function calls another function inside a loop, TurboFan may copy that inner function's code directly into the outer one, eliminating the overhead of the function call entirely.
function getPrice(item) {
return item.price * 1.05; // 5% tax
}
function getTotal(items) {
return items.reduce((sum, item) => sum + getPrice(item), 0);
}function getTotal_Optimized(items) {
let sum = 0;
let length = items.length;
for (let i = 0; i < length; i++) {
let item = items[i];
// --- INLINED getPrice(item) ---
// No function jump happens here.
// The CPU just sees the raw math.
let priceWithTax = item.price * 1.05;
// ------------------------------
sum += priceWithTax;
}
return sum;
}On-Stack Replacement
What if a function is called once but runs a loop for ten million iterations? The function never gets "warm" by call count, but the loop is extremely hot.
V8 solves this with On-Stack Replacement (OSR). The loop starts running in slow interpreted bytecode. In the background, TurboFan compiles an optimized version. When it's ready, V8 pauses mid-loop, swaps the execution frame on the stack for the new optimized one, and resumes. Now it's running at full speed.
For example, if you have a function that processes a large array, Turbofan can optimize the loop even if the function itself isn't called multiple times:
function processLargeArray(arr) {
let sum = 0;
for (let i = 0; i < arr.length; i++) {
sum += arr[i];
}
return sum;
}Wait! Can we move from Ignition to TurboFan without going through Sparkplug and Maglev? Yes, if the loop is hot enough, V8 can skip the intermediate tiers and jump straight to TurboFan. The pipeline is flexible like that.
By the way, OSR isn't just for turboFan. Maglev can also do OSR if it sees a hot loop. The difference is that Maglev's optimized code still has guards and checks, while TurboFan's code is fully optimized with no safety nets.
Deoptimization: When the Bet Fails
TurboFan's speed comes entirely from its bets. Bets can be wrong.
If TurboFan assumed add() always receives integers, and on the 10,001st call you pass a string, the generated machine code is now invalid for that input. V8 can't crash. It has to handle this gracefully.
This is deoptimization: V8 detects the broken assumption, discards the optimized code, reconstructs the interpreter state, and falls back to Ignition bytecode.
But why not to maglev? or sparkplug? Because due to assumptions we have made in maglev and sparkplug during machine code generation, we don't have the guaranteed-correct execution state that v8 can fall back to. Ignition is the only tier that has the full, correct execution state for any possible input. After reaching ignition, the function can re-warm and climb the pipeline again.
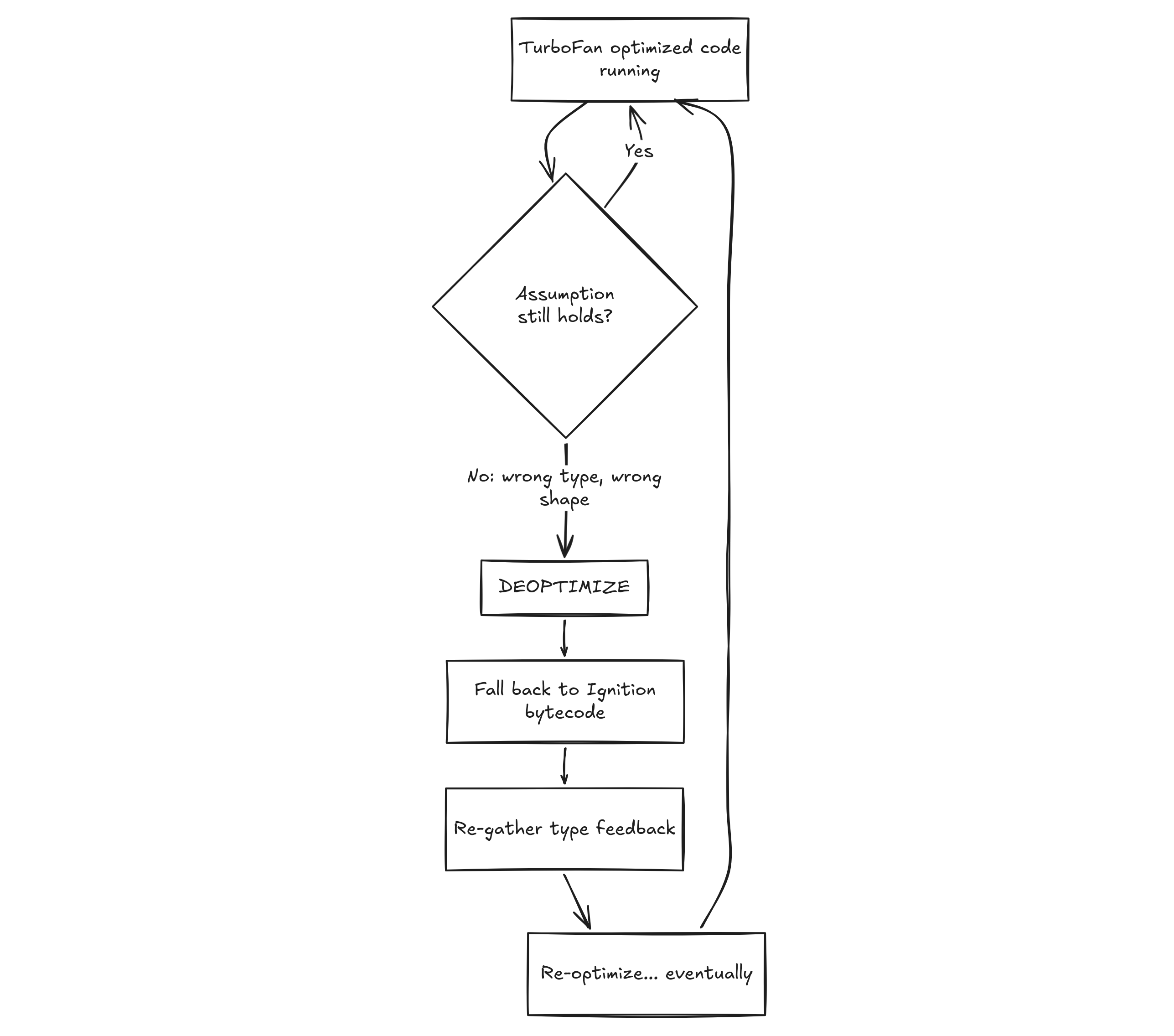
A single deopt isn't a disaster. What kills performance is a deopt loop, where V8 optimizes, immediately hits a deopt, re-optimizes, hits another deopt, and so on forever. The function is stuck oscillating between hot and cold.
Demo
Lets run some code and see this optimization pipeline in action. Run this following code with node --trace-opt --trace-deopt program.js to see the optimization and deoptimization logs in the console.
function add(a, b) {
return a + b;
}
// 1. Warm up the function to reach Maglev/TurboFan thresholds
for (let i = 0; i < 20000; i++) {
add(i, i + 1);
}
// 2. Trigger a deoptimization by changing the types
// The engine expects Numbers, but we will pass Strings.
console.log("--- Triggering Deopt ---");
add("hello", "world");You will see logs like this in the console:
// 1. Function becomes "hot." V8 promotes it to Maglev (fast baseline).
[marking <JSFunction add> for optimization to MAGLEV, reason: hot and stable]
[completed compiling <JSFunction add> (target MAGLEV) - took 0.208 ms]
// 2. The loop is still running! V8 uses On-Stack Replacement (OSR)
// to swap the engine for Maglev mid-loop.
[compiling <JSFunction> (target MAGLEV) OSR]
[completed compiling <JSFunction> (target MAGLEV) OSR - took 0.221 ms]
// 3. The loop stays hot. V8 pulls in the heavy hitter: TurboFan.
// Notice it takes ~6x longer to compile than Maglev.
[compiling <JSFunction> (target TURBOFAN_JS) OSR]
[completed compiling <JSFunction> (target TURBOFAN_JS) OSR - took 1.292 ms]
--- Triggering Deopt ---
// 4. Types changed (Number -> String). The optimized code "bails out."
// V8 discards the Maglev code and falls back to the Interpreter.
[bailout (reason: not a Smi): deoptimizing <JSFunction add>, <Code MAGLEV>]The four-tier pipeline now has a clear practical implication: V8 rewards predictability.
Every tier is making increasingly aggressive assumptions about your code. The more consistent your types, shapes, and values are, the higher V8 can push your code up the pipeline, and the longer it stays there. If your code is unpredictable, V8 will keep it in the lower tiers, where it's safe but slower.