Engineering the Real-Time Web: Why HTTP Was Never Enough
TL;DR: We are going to rediscover WebSocket from the ground up in this series. In this part, we start with what real-time communication actually needs, then try to get it from HTTP. Every attempt gets closer. None of them quite make it.
What Does Real-Time Actually Need?
Think about a chat app. You type a message. It appears on your friend's screen immediately. No refresh. No button click. It just arrives.
Now think about Google Docs. You edit a sentence and your colleague sees the cursor moving in real time. Or a multiplayer game where you move your character and every other player sees it within milliseconds. Or a live stock dashboard where a price updates on the exchange and every connected client sees the new number instantly.
These feel like different problems. But underneath, they all need the same things from their network connection. Let me name them now, because the rest of this post is the story of trying to find a protocol that satisfies all four.
Persistent connection. The connection must stay open. In a chat app, you are not sending a message every second. But you need to be ready to send or receive at any moment. Opening a brand new connection for every exchange takes time. There is a handshake, latency, overhead. At real-time speeds, that cost is unacceptable. The connection needs to exist before the message arrives, ready and waiting.
Full-duplex connection. Both sides need to be able to send data, not just the server pushing and the client receiving. That is bidirectional. But bidirectional alone is not enough. What we actually need is both directions on the same connection, simultaneously, without either side waiting for the other to finish. That is full-duplex. One pipe, both directions, at the same time.
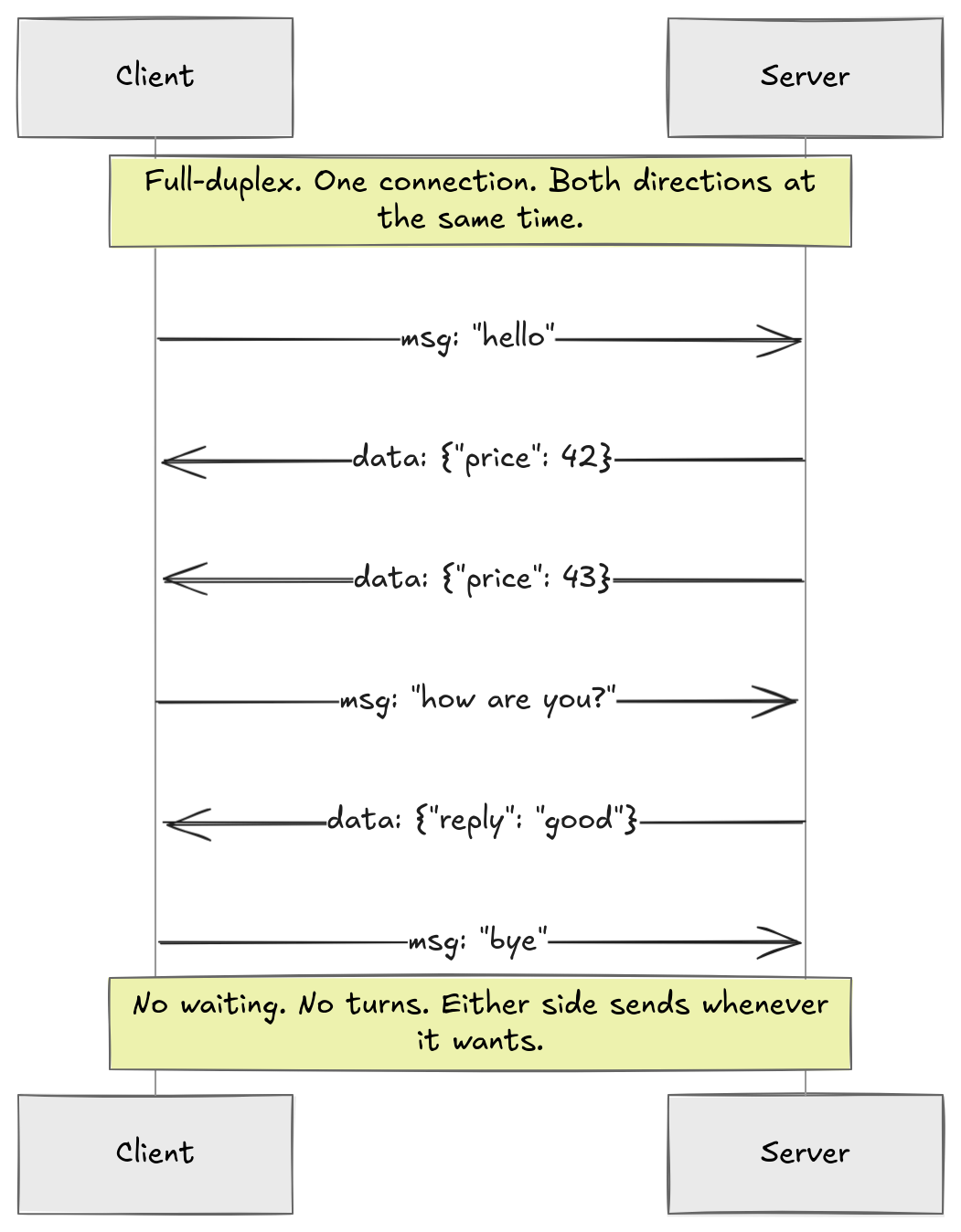
Low latency. Data must arrive within milliseconds of being sent. The moment something happens on one side, the other side should know. This sounds obvious but it rules out a surprising number of approaches, as we will see.
Reliable and ordered delivery. A chat message that arrives corrupted is useless. A message that arrives out of order is confusing. We need delivery guarantees: every message arrives, intact, in the order it was sent. The good news is we do not have to solve this ourselves. TCP handles it at the transport layer.
Survives real infrastructure. The connection must work through the actual internet, not some idealized lab network. That means firewalls that block unfamiliar ports, corporate proxies that only pass HTTP traffic, NAT devices that silently kill idle connections. Any protocol we build needs to survive all of this without asking anyone to reconfigure their network.
Five requirements. Keep them in mind.
Trying HTTP
HTTP is what the browser already speaks. Every server understands it. Every piece of infrastructure between a client and a server is built around it. So the natural first move is obvious: can we squeeze real-time behavior out of HTTP?
To answer that, we need to understand what HTTP actually is.
When a browser loads a webpage, it opens a TCP connection to the server and sends a request. The resource it wants, plus some metadata. The server reads it, writes a response, and that is it. Exchange complete. Under HTTP/1.0, the TCP connection closes immediately after. Under HTTP/1.1, the connection can stay open and be reused for the next request. But the model does not change either way: the client asks, the server answers, and the server goes silent until the client asks again.
The server has no mechanism to speak first. It cannot say "something happened, here is new data" without waiting for the client to open a door. That is the fundamental constraint we are working against.
So. Can we work around it?
Polling
The simplest idea: just have the client ask on a fixed timer.
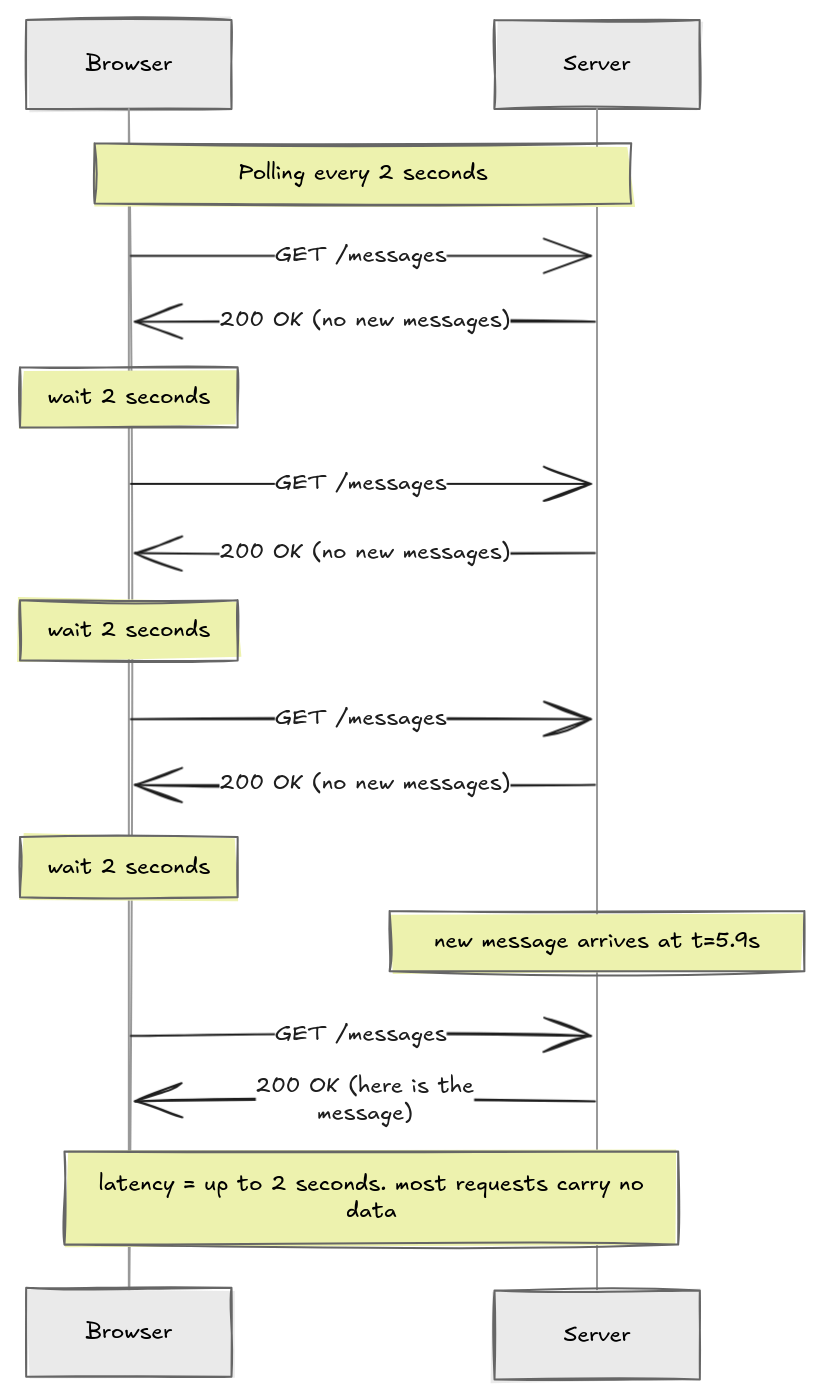
Okay, this technically works. But think about what is actually happening here. The client fires a request every two seconds regardless of whether anything has changed. Most of those requests come back empty. You are generating a constant stream of traffic that carries almost no information. Burning network bandwidth and server CPU just to check if something happened.
And the latency is bounded by the interval. If something happens 100ms after a request just completed, the client will not know for another 1900ms. You can shrink the interval to reduce latency, but that makes the waste worse.
Long Polling
Here is a smarter idea: instead of the server answering immediately with "no", it holds the connection open until it actually has something to say.
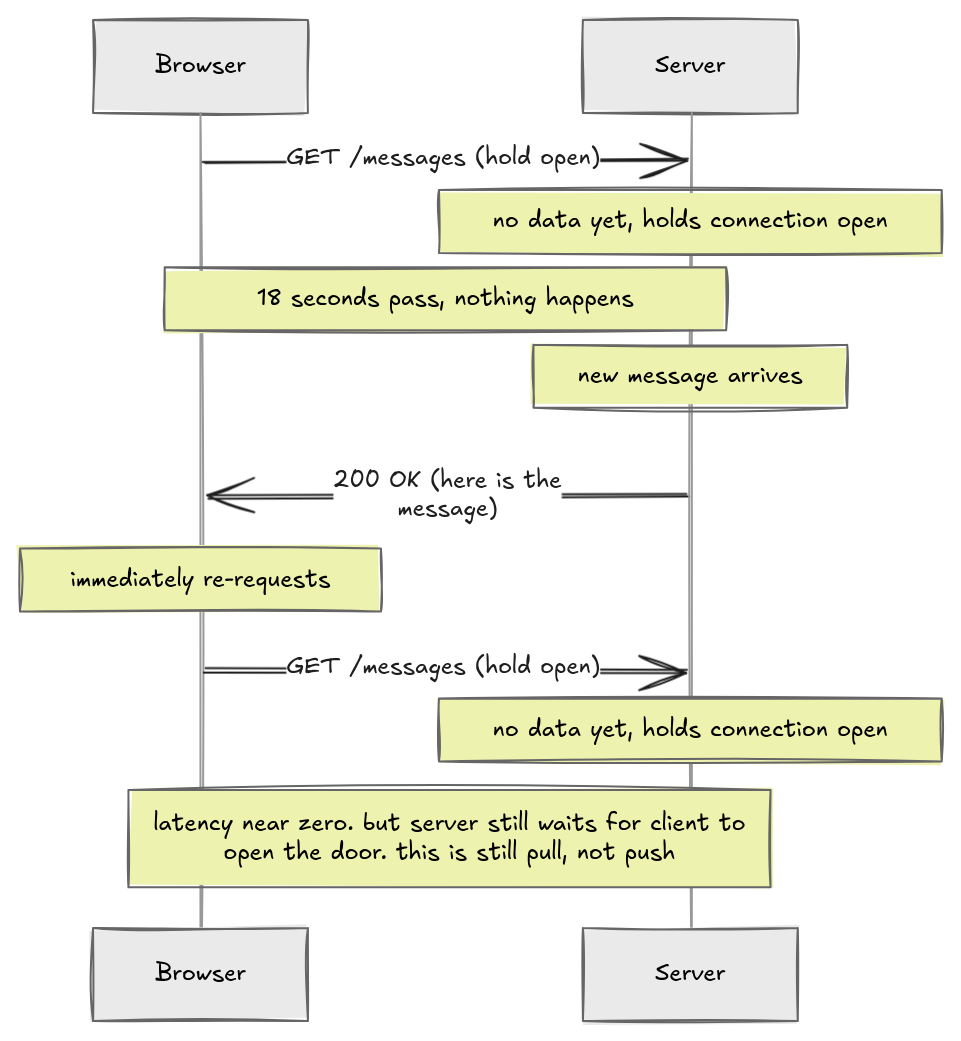
Latency drops to near zero. The moment the server has data, it responds. No waiting for the next poll interval. That is a real improvement.
But look at what is still true. The server can only speak because the client opened a connection first. The server is sitting there with data it wants to send, but it cannot send anything until a request arrives to respond to. If the client's connection times out before data arrives, the server sends an empty response and the client immediately re-requests. The whole thing is the client repeatedly handing the server a telephone and saying "call me back on this."
This is a pull model. The client is always the one reaching out. Even when it looks like the server is pushing data, the server is actually responding. What we want is genuine push. The server gets an event and sends it immediately, on its own terms.
Long polling cannot give us that. It is the best approximation of push that request-response allows. But it is still request-response underneath.
Server-Sent Events
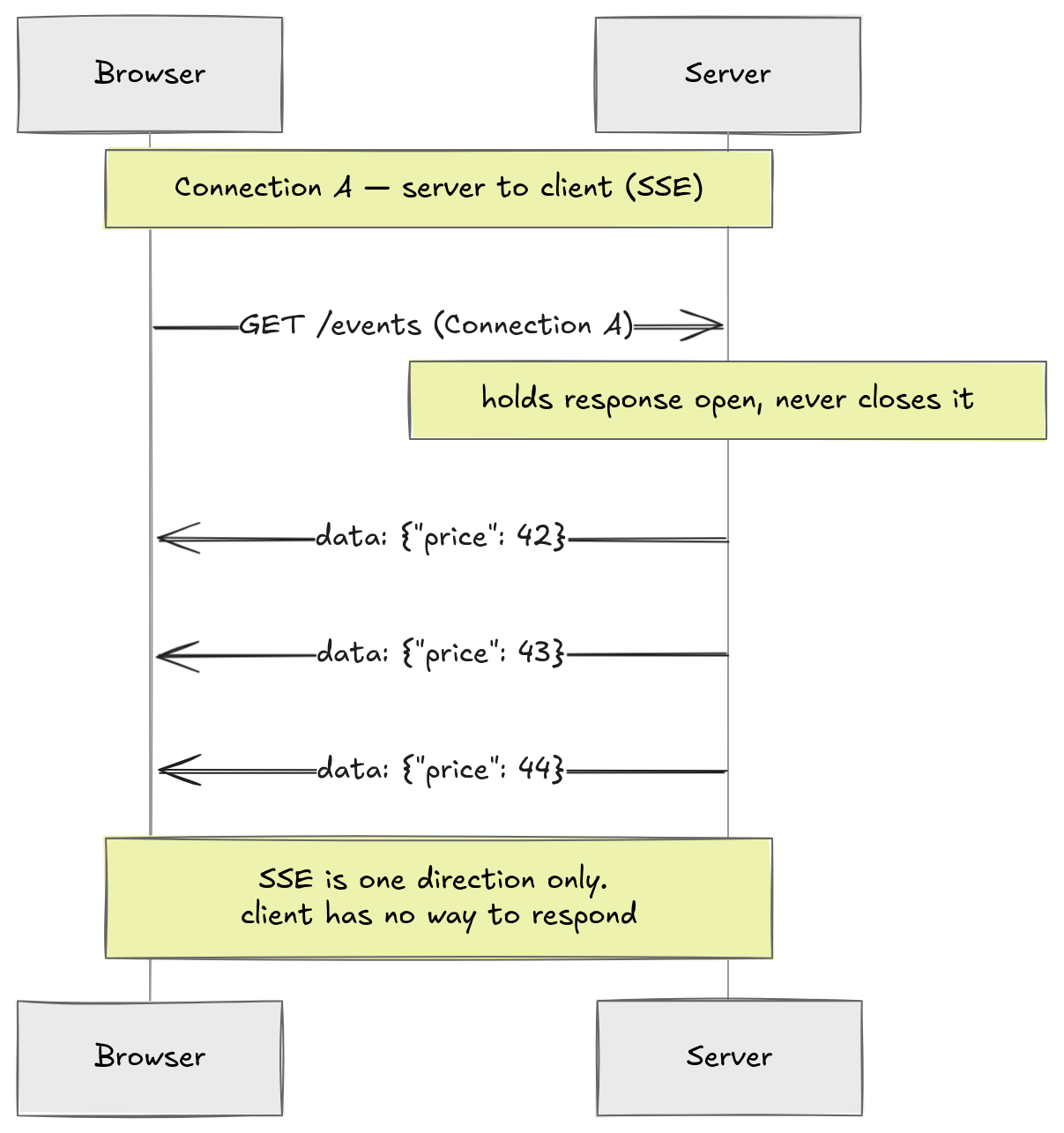
Eventually the web standardized a proper version of the streaming idea. Server-Sent Events (SSE): the client makes one HTTP request, the server holds the response open indefinitely, and writes events into it in a defined text format.
Client: GET /events HTTP/1.1
Server: HTTP/1.1 200 OK
Content-Type: text/event-stream
data: {"price": 42}
data: {"price": 43}
data: {"price": 44}
...
This is actually pretty elegant. The server just keeps writing. The browser keeps reading. The browser has native support through the EventSource API. One line of JavaScript and you have a live event stream. This is genuine server push. The server decides when to send. The client never has to re-request.
But then you try to send something back and you hit the wall.
If the client needs to send data to the server, a chat message, a user action, anything, it has to open a separate HTTP request. That request goes through the normal request-response cycle. Now you have two connections open for one logical session: the SSE connection for server-to-client data, and a separate connection for client-to-server data.
SSE solves the push problem for one direction. It has no answer for the other.
The Deeper Problem: One Pipe, Two Jobs
Every approach so far hits the same wall. An HTTP/1.1 connection is a synchronous pipe. One request goes in, one response comes out, in sequence. Until that response is complete, the connection cannot carry anything else.
SSE and long polling keep a response permanently open. That is the whole point of them. But that means the pipe is permanently occupied. The client cannot send data through it. So it has to open a second connection.
Now the server sees two separate TCP streams from the same browser. Nothing in HTTP links them. They are two anonymous connections arriving from the same IP address. The server has no idea they belong to the same user session.
So the application has to build the link manually. The client attaches a session token to every request. The server maintains a lookup table, typically in something like Redis, mapping each token to its open SSE or long poll connection. When a message arrives on connection A with token abc123, the server looks up abc123, finds connection B, and pushes the response through it.
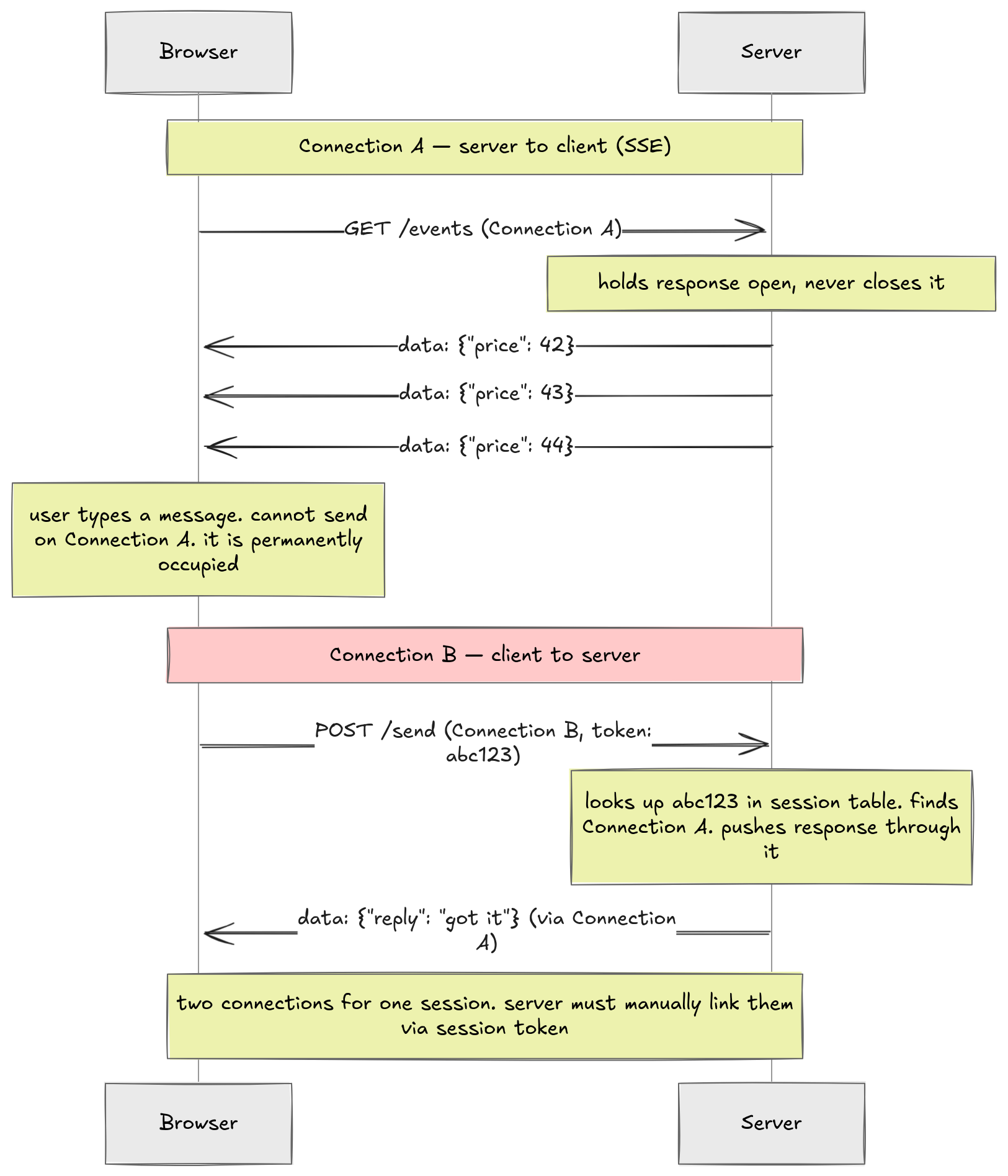
Think about what that server code actually looks like. On every incoming POST, you parse the session token, hit the lookup table, find the right SSE response object, and write to it. You have to handle the case where the SSE connection dropped and the token is stale. You have to clean up the table when connections close.
None of this is your actual problem. Your problem is sending a chat message. All of this other code exists purely because HTTP was never designed for two-way communication.
What about HTTP/2? HTTP/2 introduced multiplexing. Multiple logical streams over one TCP connection. So the SSE stream might be stream 3 and your POST might be stream 5. They share one TCP pipe. The two-physical-connections problem goes away.
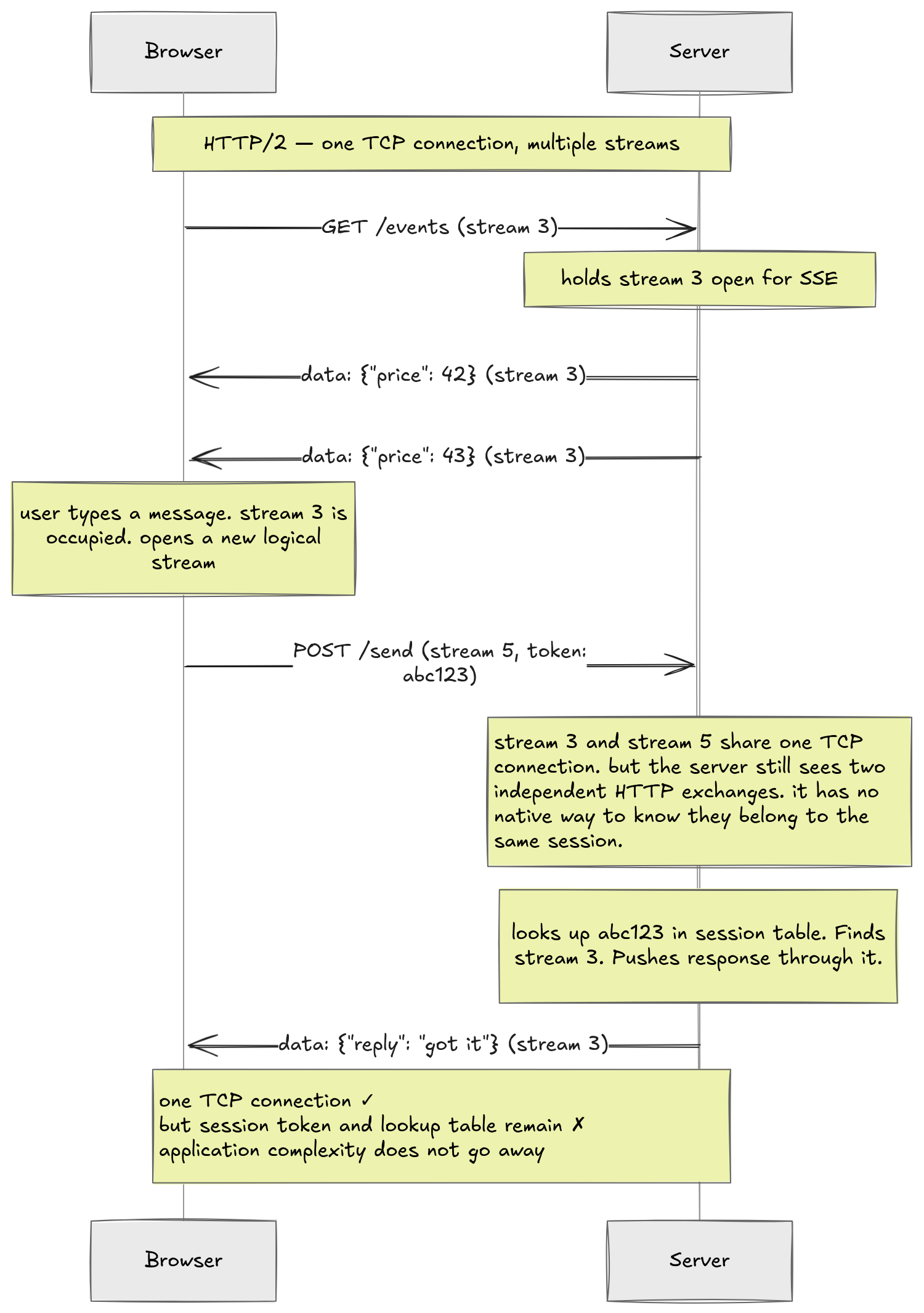
But the server still sees two independent HTTP exchanges. Stream 3 and stream 5 arrive as separate requests. The server has no native way to know they belong to the same user. The session token and the lookup table are still there. The transport got cleaner. The application logic did not.
Where We Are
Let's look at the full picture:
| Approach | Persistent | Full-duplex Connection | Low Latency | Reliable + Ordered | Infrastructure |
|---|---|---|---|---|---|
| Polling | ✓ | ✗ | ✗ | ✓ | ✓ |
| Long Polling | ✓ | ✗ | ✓ | ✓ | ✓ |
| SSE | ✓ | ✗ | ✓ | ✓ | ✓ |
| SSE + HTTP/2 | ✓ | ✗ | ✓ | ✓ | ✓ |
Every approach satisfies reliable and ordered delivery for free, because they all run on TCP. Every approach fails on the same requirement: a full-duplex connection. HTTP was built around one model. Client asks, server answers. No amount of cleverness on top of that model changes what it fundamentally is.
So maybe we need to go deeper. HTTP runs on top of TCP. What does TCP actually look like at the connection level? Does it have the properties we need? Can we build something directly on top of it that gives us the real-time web without all of these hacks?
We will find out next.